关于 GIL #
- Pyhton的全局解释器锁
协程 #
- 协程其实就是一个线程, 在执行过程中, 在程序内部中断,然后转而执行别的程序,在适当的时候再返回来接着执行
优势 #
- 最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
- 第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
- 因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
原因 : #
- cpython解释器中存在一个GIL(全局解释器锁),他的作用就是保证同一时刻只有一个线程可以执行代码,
- 因此造成了我们使用多线程的时候无法实现并行。
解决方案法 : #
更换解释器 比如使用jpython(java实现的python解释器)
使用多进程完成多任务的处理
Python语言和GIL没有关系。仅仅是由于历史原因在Cpython虚拟机(解释器),难以移除GIL。
GIL:
全局解释器锁。
- 每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程可以执行代码。
- 线程释放GIL锁的情况: 在IO操作等可能会引起阻塞的system call之前,可以暂时释放GIL,但在执行完毕后, 必须重新获取GIL Python 3.x使用计时器(执行时间达到阈值后,当前线程释放GIL)或Python 2.x,tickets计数达到100 Python使用多进程是可以利用多核的CPU资源的。 多线程爬取比单线程性能有提升,因为遇到IO阻塞会自动释放GIL锁
结论:
- 在 处理像科学计算 这类需要持续使用cpu的任务的时候 单线程会比多线程快
- 在 处理像IO操作等可能引起阻塞的这类任务的时候 多线程会比单线程
yield函数 #
- 生成器函数, 可以理解为暂停,程序会暂停在yield的地方, 等待下一次调用 next() 时, 程序又会执行一次, 然后继续执行
可以通过打断点来进行理解, 让程序一步一步执行, 查看程序到底执行到了那里, 暂停到了那里
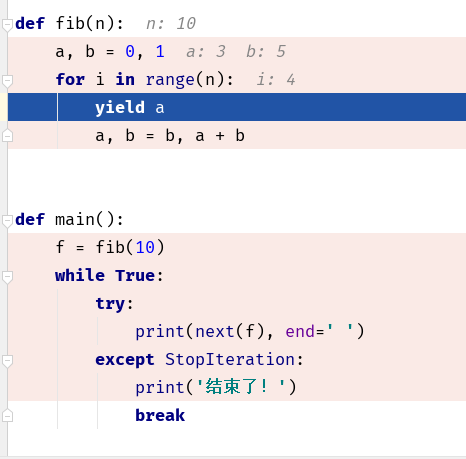
next() 让 yield 向下执行
send(n) 将值传入到 yield , 让后向下执行
import time
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] 消费者:%s' % n)
time.sleep(1)
r = 'CONSUMER,结束状态!'
def produce(c):
next(c) # 启动程序 ,让执行到 yield 处, 暂停, 等待
n = 0
while n < 3:
n += 1
print('n的值:%s...' % n)
# 将 n 传入到 yield 中, yield r 的值 替换为 n,
# 同时 将原来的r 的值获取到, 赋值给当前的 r
r = c.send(n)
print('r的值:%s' % r)
print('--' * 20)
c.close()
def main():
c = consumer()
produce(c)
if __name__ == '__main__':
main()
总结 #
- next() 激活, 向下执行
- yield 暂停 停止, 并且返回值
- sent() 激活 并且 替换 yield 的值
aiohttp #
官方文档 #
http://aiohttp.readthedocs.io/en/stable/
asyncio #
asyncio 是 Python 3.4 版本引用的标准库, 直接内置了对异步IO 的支持
asyncio的编程模式就是一个消息循环,我们从asyncio模块中直接获取一个 EventLoopd的引用, 然后把需要执行的协程扔到 EventLoop 中执行, 就实现了异步 IO,异步 IO 不会中断 CPU ,CPU 可以 继续其他的请求
@asyncio.coroutine和anync + await效果相同, 只是写法不同
#
async和await是针对coroutine(/,kəuru:’ti:n/)的新语法(最新添加的保留关键字),要使用新的语法,只需要做两步简单的替换:
- 把
@asyncio.coroutine替换为async - 把
yield from替换为await。
下面的函数得到相同的结果
import asyncio
@asyncio.coroutine
def hello(n):
print('hello, world! ' + n)
r = yield from asyncio.sleep(3) # 等待 3s 但是程序马上启动了第二个任务
print('hello complete! ' + n)
async def hello(n):
print('hello, world! ' + n)
r = await asyncio.sleep(3)
print('hello complete! ' + n)
loop = asyncio.get_event_loop()
task = asyncio.wait([hello('AAAAAA'), hello('BBBBBB')])
loop.run_until_complete(task)
loop.close()
我们可以在耗时较长的任务前中添加 await来让其实现多线程的并发
实际就是在 判断为耗时较长的 程序代码前 添加 await
使用自定义域名服务器 #
aiohttp #
异步 http 请求
底层需要aiodns支持:
from aiohttp.resolver import AsyncResolver
resolver = AsyncResolver(nameservers=["8.8.8.8", "8.8.4.4"])
conn = aiohttp.TCPConnector(resolver=resolver)
为TCP sockets添加SSL控制: #
默认情况下aiohttp总会对使用了HTTPS协议(的URL请求)查验其身份。但也可将verify_ssl设置为False让其不检查:
r = await session.get('https://example.com', verify_ssl=False)
如果你需要设置自定义SSL信息(比如使用自己的证书文件)你可以创建一个ssl.SSLContext实例并传递到ClientSession中:
sslcontext = ssl.create_default_context(
cafile='/path/to/ca-bundle.crt')
r = await session.get('https://example.com', ssl_context=sslcontext)
代理支持 #
aiohttp 支持 HTTP/HTTPS形式的代理。你需要使用proxy参数:
async with aiohttp.ClientSession() as session:
async with session.get("http://python.org",
proxy="http://some.proxy.com") as resp:
print(resp.status)
同时支持认证代理:
async with aiohttp.ClientSession() as session:
proxy_auth = aiohttp.BasicAuth('user', 'pass')
async with session.get("http://python.org",
proxy="http://some.proxy.com",
proxy_auth=proxy_auth) as resp:
print(resp.status)
也可将代理的验证信息放在url中:
session.get("http://python.org",
proxy="http://user:pass@some.proxy.com")
与requests(另一个广受欢迎的http包)不同,aiohttp默认不会读取环境变量中的代理值。但你可以通过传递trust_env=True来让aiohttp.ClientSession读取HTTP_PROXY或HTTPS_PROXY环境变量中的代理信息(不区分大小写)。
async with aiohttp.ClientSession() as session:
async with session.get("http://python.org", trust_env=True) as resp:
print(resp.status)
设置超时 #
默认情况下每个IO操作有5分钟超时时间。可以通过给ClientSession.get()及其同类组件传递timeout来覆盖原超时时间:
async with session.get('https://github.com', timeout=60) as r:
...
None 或者0则表示不检测超时。 还可通过调用async_timeout.timeout上下文管理器来为连接和解析响应内容添加一个总超时时间:
import async_timeout
with async_timeout.timeout(0.001):
async with session.get('https://github.com') as r:
await r.text()
愉快地结束: #
当一个包含ClientSession的async with代码块的末尾行结束时(或直接调用了.close()),因为asyncio内部的一些原因底层的连接其实没有关闭。在实际使用中,底层连接需要有一个缓冲时间来关闭。然而,如果事件循环在底层连接关闭之前就结束了,那么会抛出一个 资源警告: 存在未关闭的传输(通道)(ResourceWarning: unclosed transport),如果警告可用的话。 为了避免这种情况,在关闭事件循环前加入一小段延迟让底层连接得到关闭的缓冲时间。 对于非SSL的ClientSession, 使用0即可(await asyncio.sleep(0)):